Architecture-Efficient
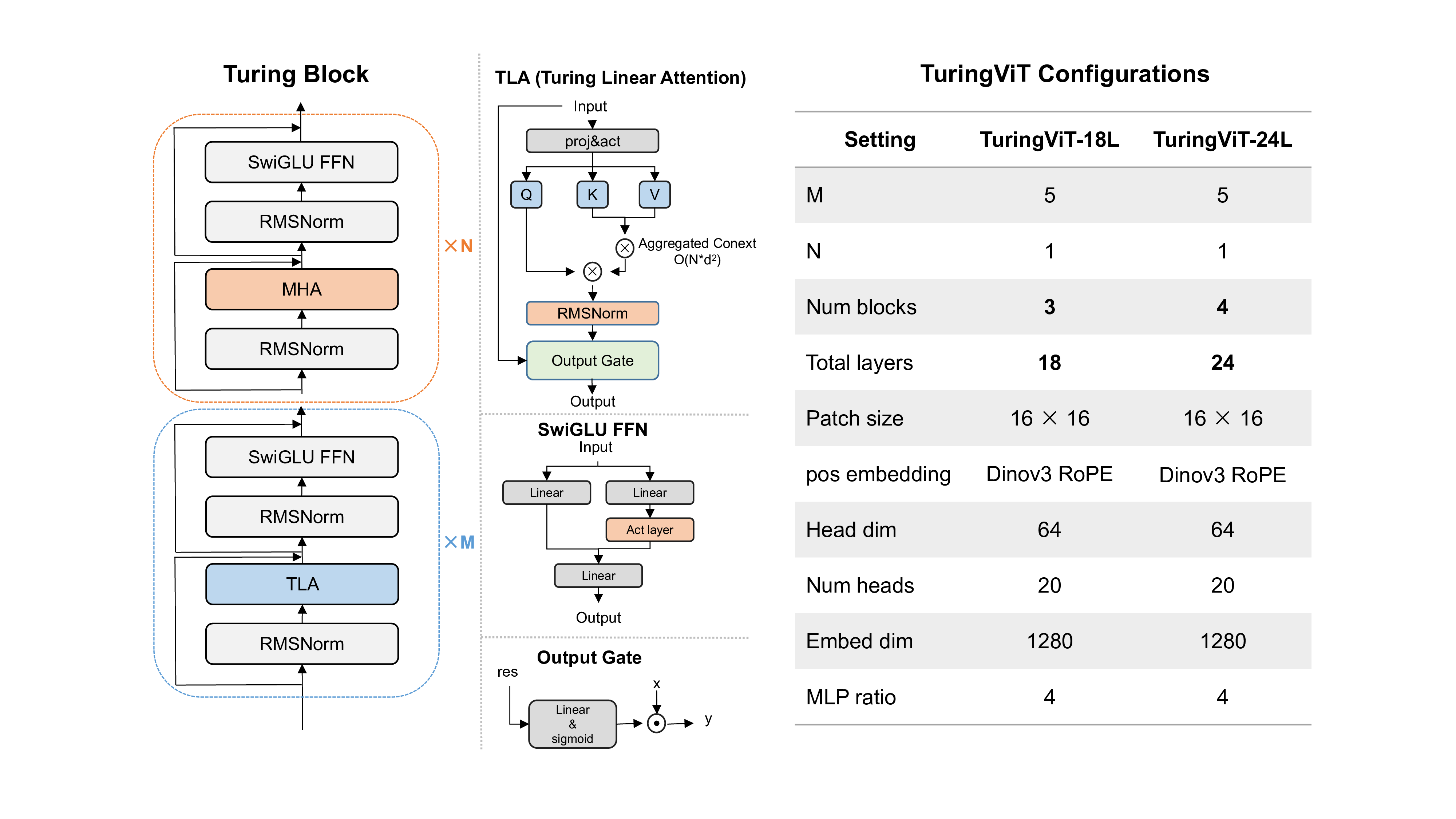
The Turing Linear Attention (TLA) dominates the stack; only 1 of every 6 layers keeps softmax MHA for global routing. Quadratic → near-linear scaling, with input-dependent gating that preserves local & high-frequency cues.
A VLM-native, data-efficient and linear-complexity Vision Transformer. We show a concrete, reproducible path for designing and training your own SOTA-level visual encoder under a controlled resource budget — outperforming leading open-source ViT baselines using only 10% of the data, with substantially flatter latency scaling for high-resolution and dynamic-resolution inputs.
TuringViT rethinks visual encoders along three orthogonal axes — architecture, data, and training — to make SOTA-level encoders trainable and customizable under realistic resource budgets.
The Turing Linear Attention (TLA) dominates the stack; only 1 of every 6 layers keeps softmax MHA for global routing. Quadratic → near-linear scaling, with input-dependent gating that preserves local & high-frequency cues.
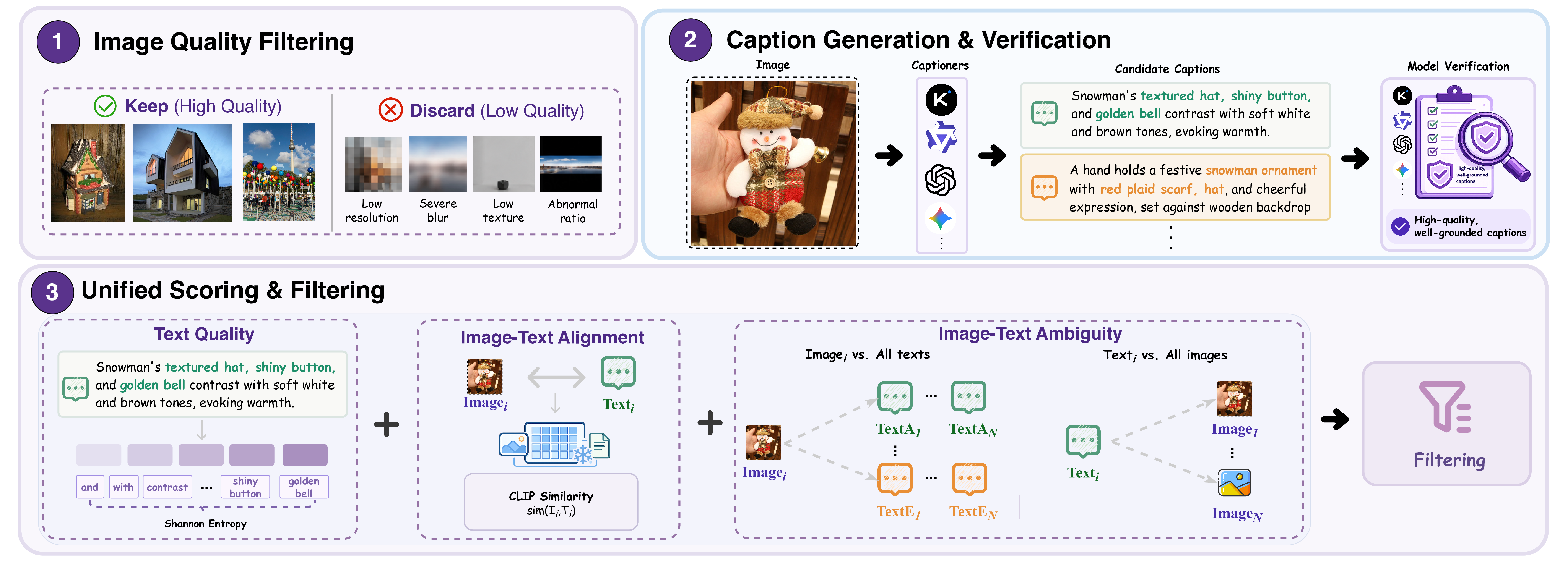
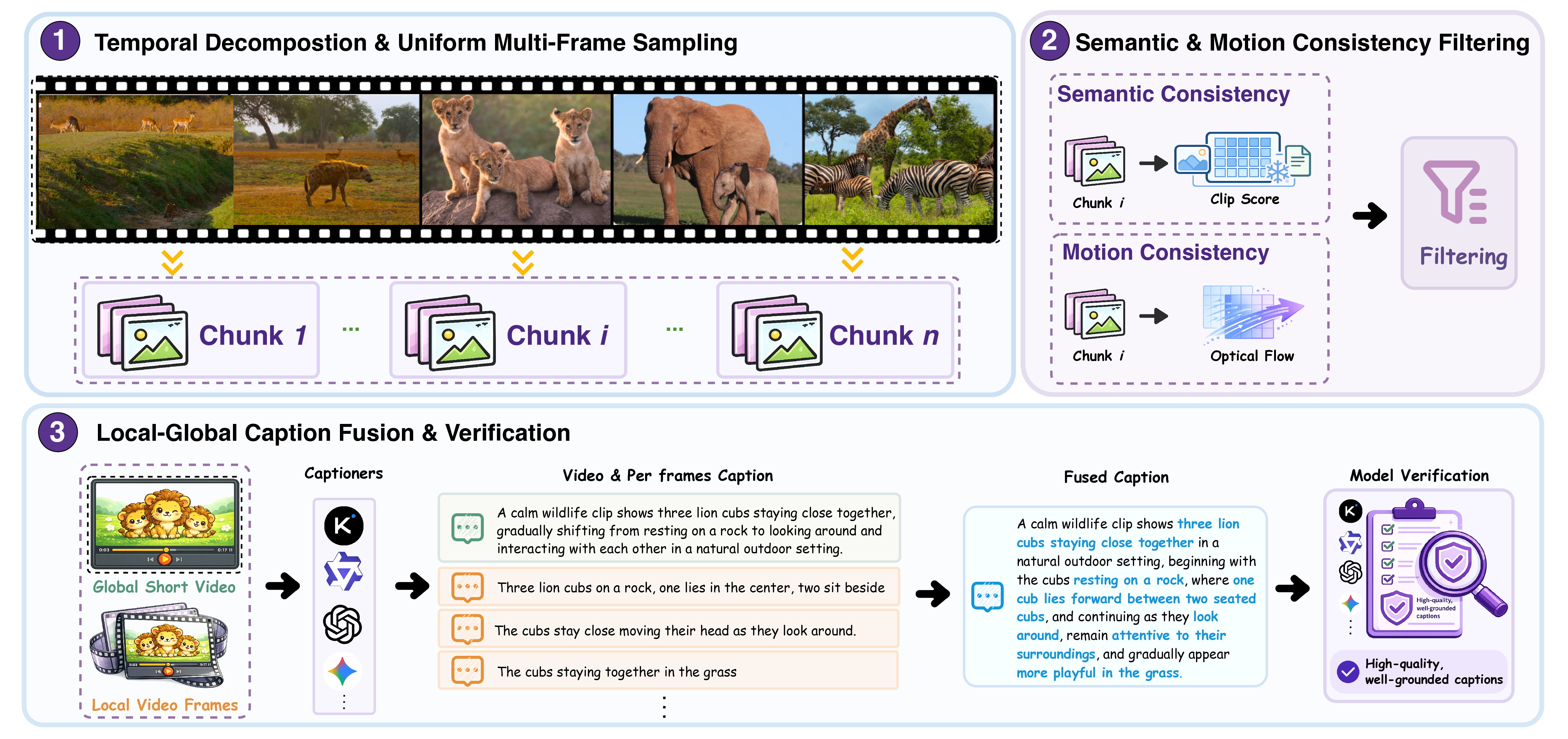
VISTA-Curation turns noisy web image–text and video–text data into grounded, discriminative, temporally informative supervision. Result: 10× data reduction without sacrificing quality.
Trained natively at dynamic resolution from the start; no post-hoc adaptation, no extra parameters when plugged into downstream VLMs. Generation-aligned objectives further bridge contrastive ViT and generative VLM training.
Five Turing Linear Attention layers handle global context at O(N). One vanilla MHA per block keeps token-level precision. The result: latency stays flat as resolution climbs.
Standard ViTs scale quadratically with visual token count. TuringViT stays flat.
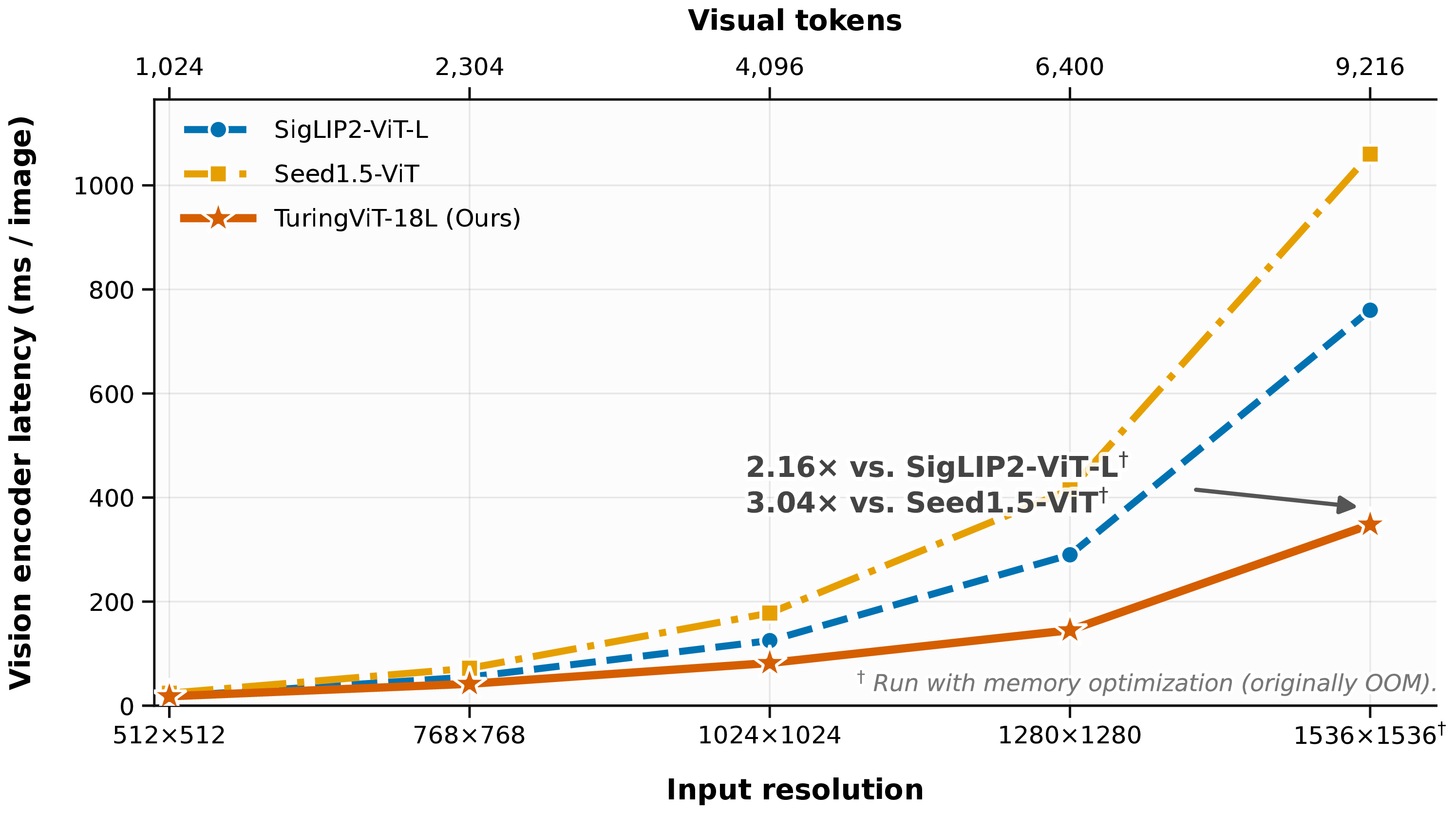
Latency measured per image using FP16 TensorRT on an NVIDIA GeForce RTX 3080 Ti (CUDA 11.6). TuringViT shows flatter high-resolution scaling than standard ViT baselines.
Vision Data Curation via Image–Video Scoring and Temporal Aggregation. Each sample is filtered, recaptioned, scored, grounded, and (for video) temporally aggregated — turning noisy web data into denser supervision.
The goal is not to introduce complex objectives, but to progressively expose the encoder to the same inputs downstream VLMs see — dynamic-resolution images, high-resolution visual content, and mixed image–video data. Both 18L and 24L follow the same recipe.
Reconstruct masked EVA02-CLIP-E features (40% mask rate) to bootstrap geometric priors before language alignment.
Aspect-preserving dynamic resolution with longer side ∈ [256, 512]; SigLIP + SuperClass loss for large-scale alignment.
Preserve original aspect ratio & resolution whenever possible, making visual preprocessing consistent with downstream VLM usage.
Mix video–text with image–text replay. T=8 frames → attention-pool → mean-pool video embedding aligned via LVT.
| MobileCLIP2-L | SigLIP2-L | Seed1.5-ViT | TuringViT-18L | TuringViT-24L | |
|---|---|---|---|---|---|
| Model configuration | |||||
| Resolution | 224 | 384 | dyn. | dyn. | dyn. |
| Pretraining data | 1.9B | 10B | 4.8B | 0.85B | 0.85B |
| Zero-shot classification | |||||
| Avg | 77.1 | 83.4 | 82.5 | 82.7 | 83.6 |
| ImageNet-1K | 81.9 | 83.1 | 83.6 | 83.1 | 83.9 |
| ImageNet-v2 | 74.7 | 77.4 | 77.6 | 77.6 | 78.0 |
| ObjectNet | 75.3 | 84.4 | 79.2 | 79.7 | 81.1 |
| ImageNet-A | 69.0 | 84.3 | 85.5 | 87.9 | 89.7 |
| ImageNet-R | 91.7 | 95.7 | 95.2 | 95.0 | 95.3 |
| ImageNet-Sketch | 69.8 | 75.5 | 74.1 | 72.8 | 73.6 |
| Zero-shot retrieval | |||||
| Avg | 72.5 | 76.7 | — | 78.9 | 79.4 |
| COCO T→I | 51.6 | 55.3 | — | 58.6 | 59.4 |
| COCO I→T | 69.0 | 71.4 | — | 75.9 | 76.0 |
| Flickr30K T→I | 77.2 | 85.0 | — | 85.7 | 86.0 |
| Flickr30K I→T | 92.0 | 95.2 | — | 95.3 | 96.3 |